Using Wget, Grep, and Sed to Download Public Domain Wallpapers From a Web Page
So here’s the situation. You come across a page with a lot of cool images that would make for great desktop wallpapers.
Of course, you could just download each one individually - like a normal person - but where’s the fun in that?
I came across this page recently:
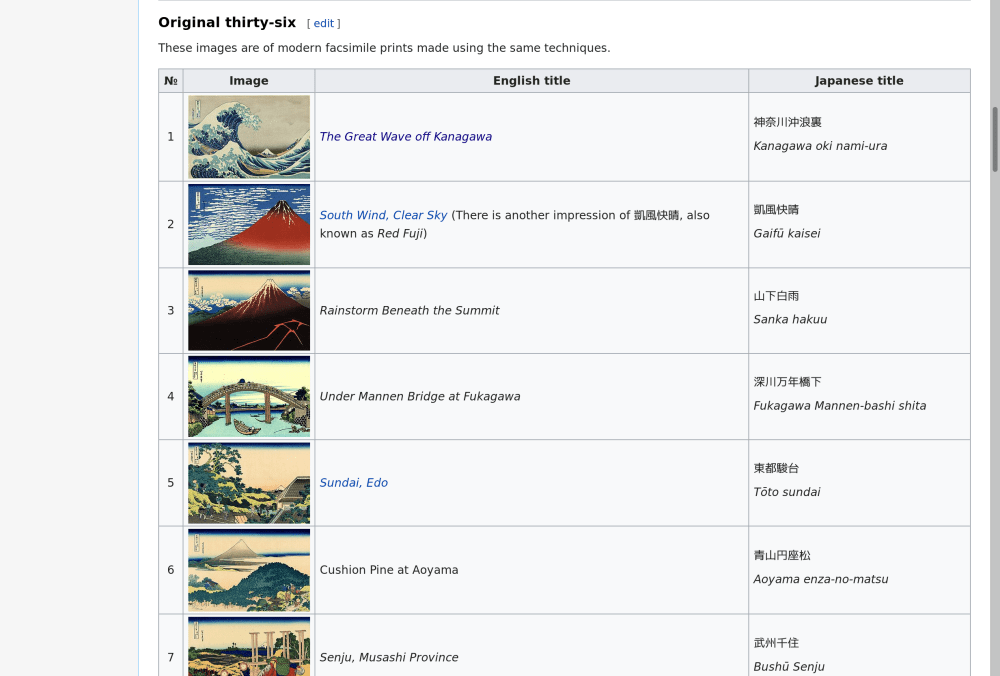
It’s the full collection of the “Thirty-six Views of Mount Fuji” paintings. (All of which are in public domain) You can check them out here
So how can we download all of these images from the command line?
Well, if you don’t care about learning how to create this project from scratch, you can skip to part 4 and get up-and-running right away.
The Tools For The Job
We will be using the following command line utilities that are most likely already installed on your Linux distribution (I believe they’re all on Mac as well).
- wget
- wget is what we will be using to download images and HTML from their respected URLs.
- grep
- Think of grep as essentially a “find tool”. It allows us to find a specific pattern in a large body of text and gives us the option to filter everything else out. We will be using its regex functionality to get image URLs.
- sed
- We will use sed as a find-and-replace tool that supports regex.
wget may not come pre-installed on your Linux distribution. No matter what distribution you are on, the wget package is most likely just called “wget”.
How This Guide is Organized
There are four parts to this guide:
- Part One: Getting The Image URLS
- Part Two: Downloading The Images
- Part Three: Getting Full-Resolution Images From Wikipedia
- Part Four: Turning It Into a Script
In the first part we’ll focus on simply created a list of all the URLs on a page.
In part two, we will actually download the images from that list using wget.
In part three, we’ll learn that the images downloaded were thumbnail images (no good for desktop wallpapers) and we will modify our method to get the full-resolution version of the images.
Finally, in part four, we will turn all of our long terminal commands into a nice little shell script that makes it easy for you to download images in the future.
Part One: Getting The Image URLS
Start by opening the terminal, creating a project folder, and cding into it. If you’re not sure how to do that, you would be better off following a beginners tutorial on the Linux command line - such as this one - before proceeding.
Once again, this is the Wikipedia page that we will be working with.
Let’s first download that page’s HTML by using wget
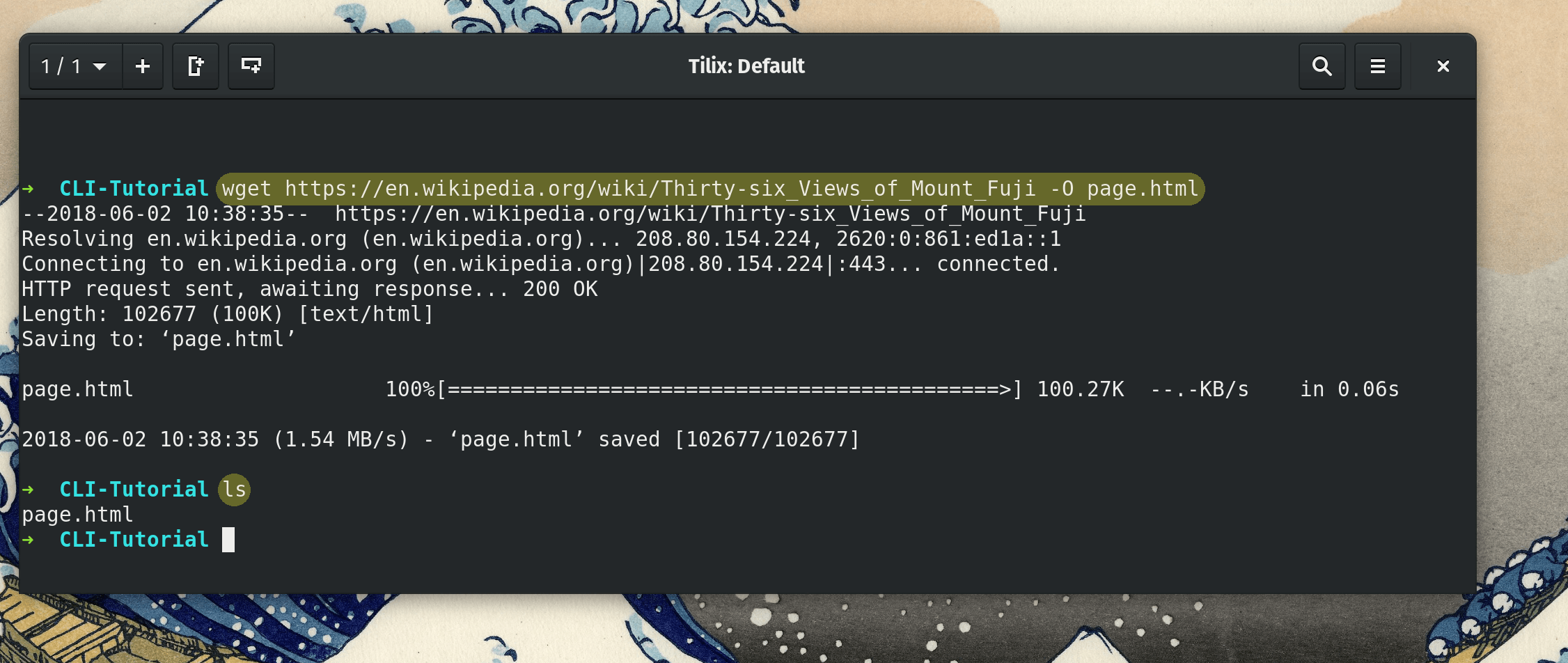
We will use wget in the fashion of wget [Image URL] -O [Our output filename].
Here is the full command to download the HTML source of that page to a file called page.html.
wget https://en.wikipedia.org/wiki/Thirty-six_Views_of_Mount_Fuji -O page.html -O page.html
Extracting the Image URLS from that page
Now we have to filter page.html to extract all of its image links.
To recap what we said about grep earlier, this is what it does:
Think of grep as essentially a “find tool”. It allows us to find a specific pattern in a large body of text and gives us the option to filter everything else out. We will be using its regex functionality.
A brief tutorial on grep
grep could either have text piped into it or it could directly process a file. Here’s an awesome grep tutorial.
To demonstrate both ways, let’s say you were to search Michael’s script (script.txt) for all occurrences of the word “Dwight”. Here are two ways to go about it.
cat script.txt | grep Dwightgrep Dwight script.txt
As a bonus, you could even go about it like this: grep Dwight < script.txt
In this situation, the second way would be the best way because it is being used as grep was intended for files. In the first way, you’re unnecessarily using the cat command to pipe the file’s text into grep.
So why would you ever consider the piped version? It comes in handy when you are dealing with a command that outputs text to the terminal.
For example: ls | grep MyImportantFile
More practical example: sudo apt list --installed | grep libreoffice (On Debian-based distros, this will list all of your installed packages and filter all of the lines with the word “libreoffice”)
Back to the task at hand
Learning the basics of grep was fun, but how do we use regular expressions?
To do so, we will use grep in the following fashion: grep -E [Our Regex Pattern] page.html
Note: Instead of
grep -Eyou could useegrepfor the same effect.
Now we need a regex pattern to be able to extract URLs from this page. Here’s the pattern I came up with:
(https?:)?//[^/\s]+/\S+\.(png|jpg)
It’s based off of a StackOverflow answer and I have made one modification to make the http/https portion optional. Why? Because a lot of image URLs on Wikipedia start with // rather than http[s]://.
In case you want to learn more about regex, I highly recommend Derek Banas series on regex. It’s where I learned most of my regex skills. Also, when you’re playing around with different regex patterns, the site regex101 is an incredible time-saver for debugging.
Let’s plug this in and run the following command to see what happens!
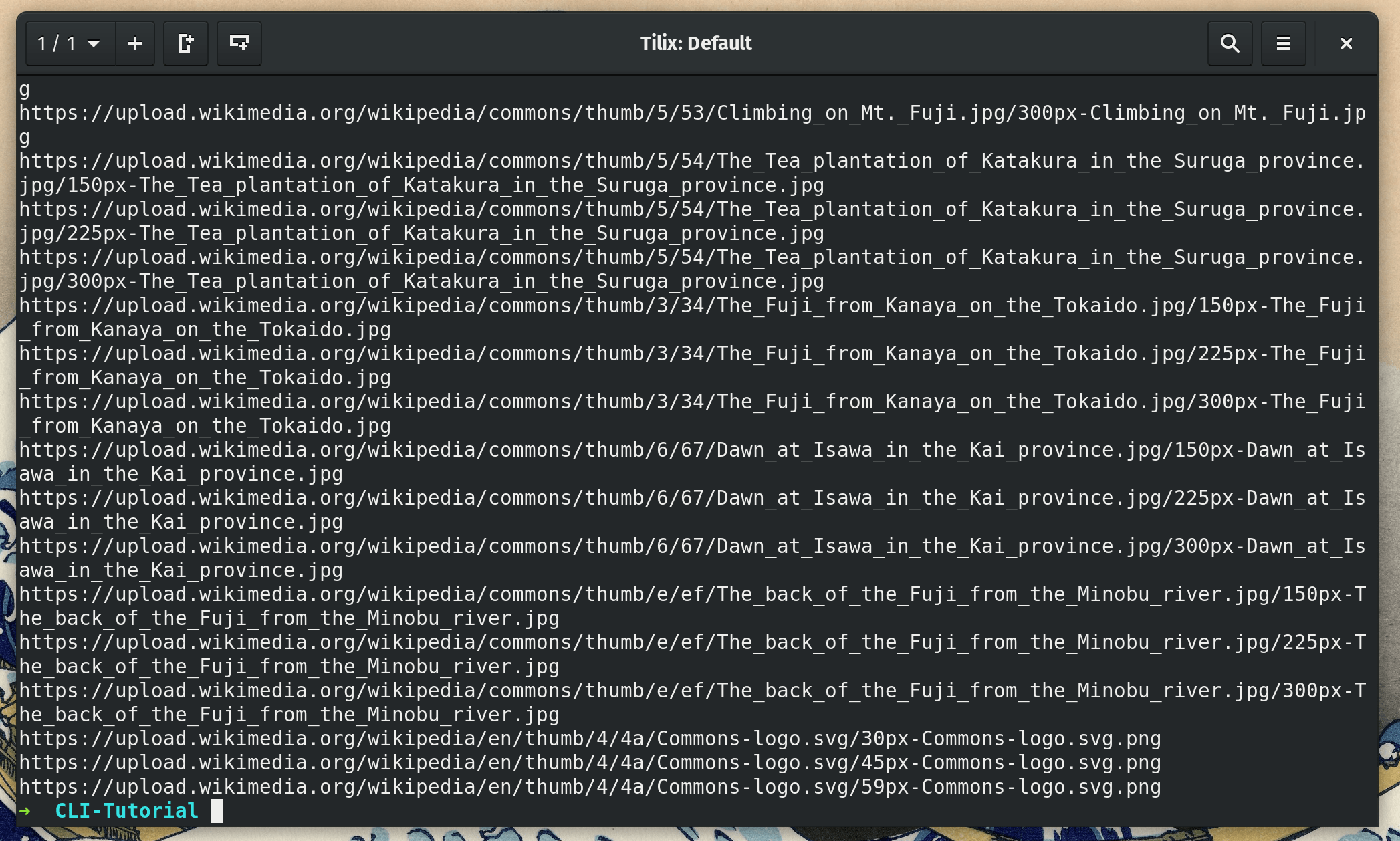
grep -E "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" page.html
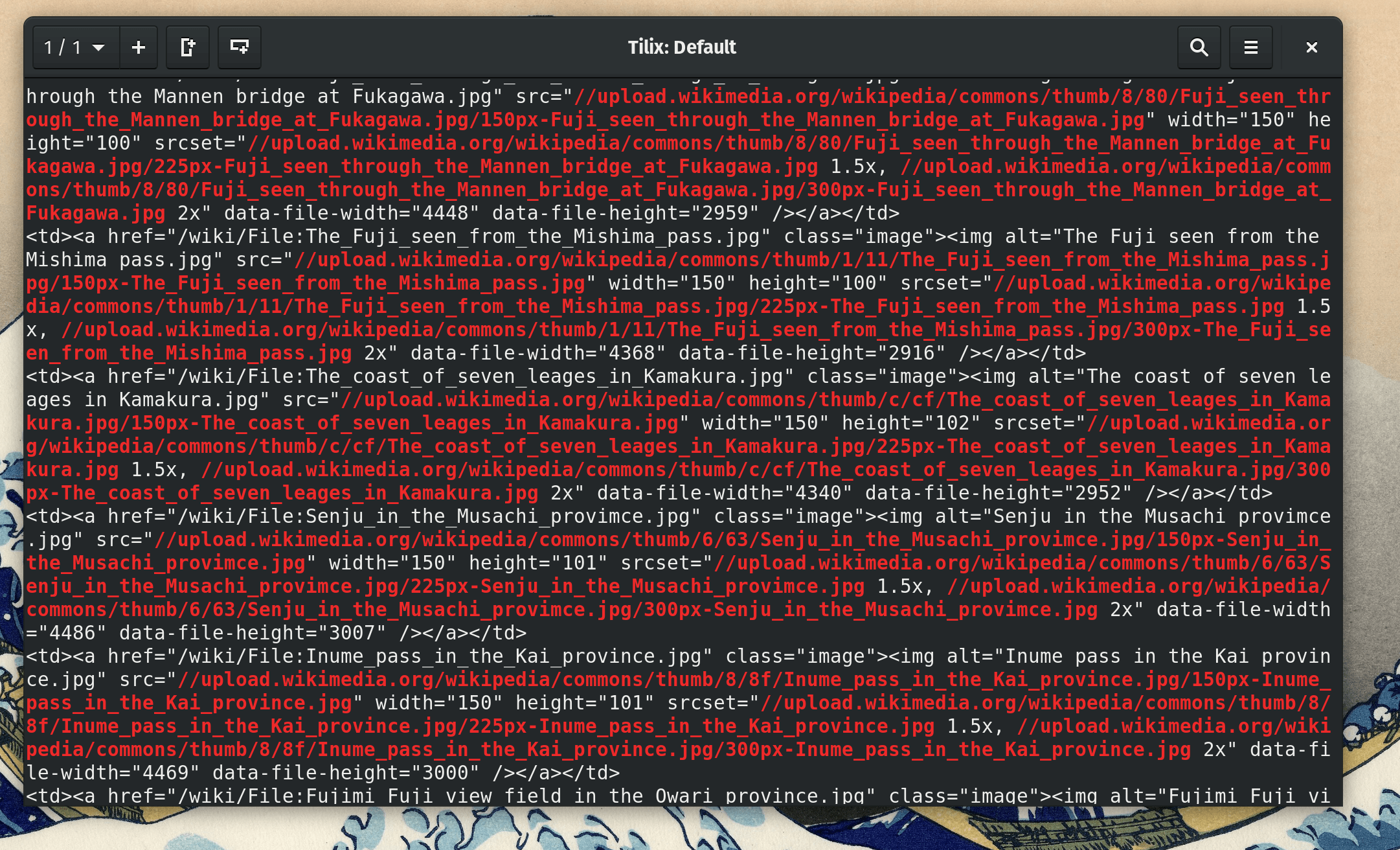
As you can see, a lot of text printing, but you can see that URLs are highlighted in red.
We can make a quick tweak to our command and only show the matched image URLs by adding the -o flag.
grep -Eo "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" page.html
Tip:
grep -Eois the same asgrep -E -o
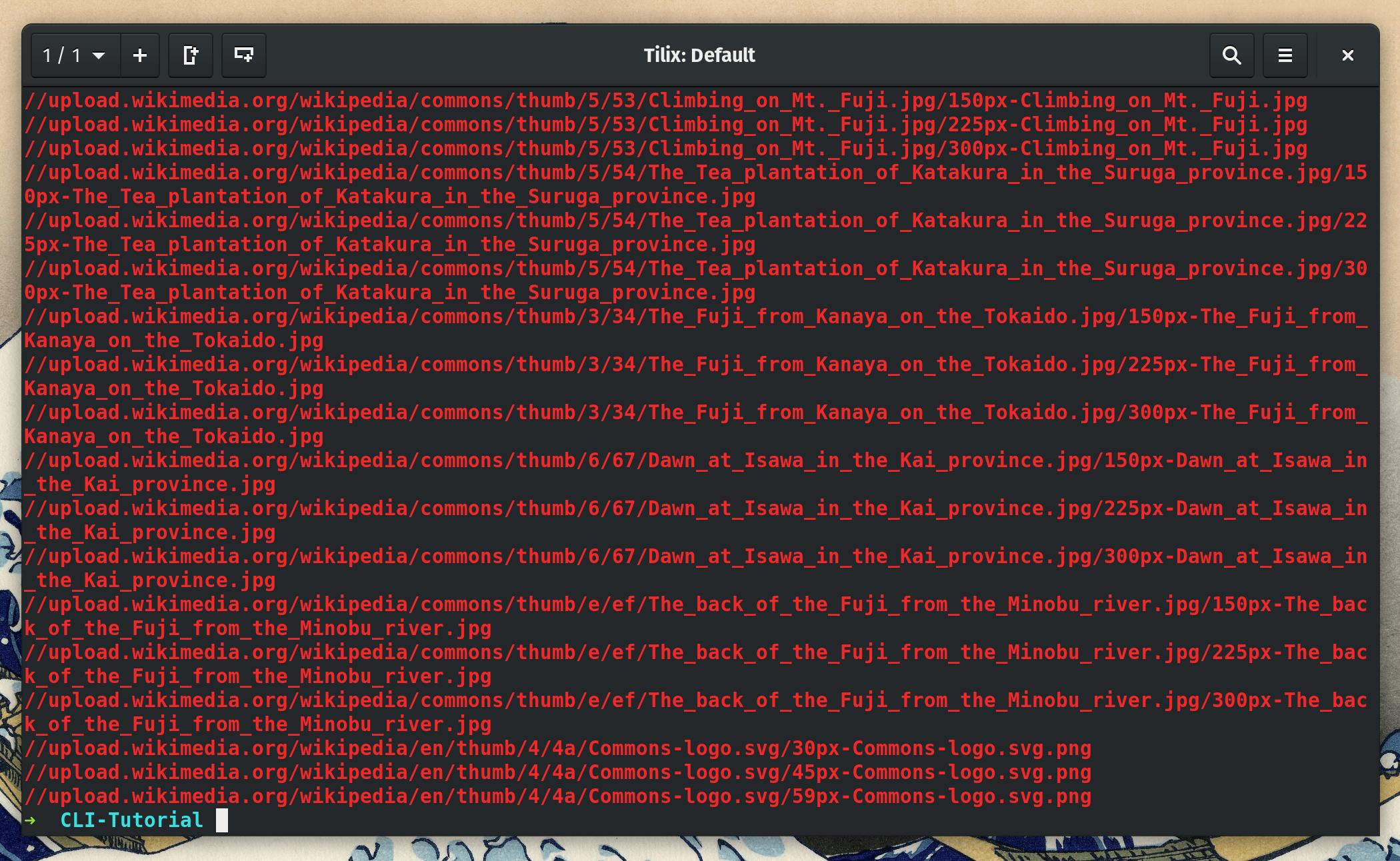
As you can see, the URLs are properly filtered now! Only problem is that we need to add “https” (https since these are Wikipedia images) to the URLs that start with “//” or wget will not be able to read them.
In order to add the https we will use the tool sed. We will use sed as a find-and-replace tool that allows for regex.
I don’t want to go too in-depth on how to use sed and will instead refer you to this GeekStuff article instead if you are interested.
Here’s how we will modify our previous command to include sed:
grep -E "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" page.html -o | sed "s/^(https?)?\/\//https\:\/\//g" -r
Give it a quick run and bingo! It works.
Let’s take a closer look at the sed potion:
sed -E "s/(^https?\:)?\/\//https\:\/\//g"
The first thing you’ll notice is the -E parameter. This tells sed that we want to use a more featureful version of regex. Without this, we couldn’t use those regex question marks that allow us to specify optional characters or words in our searching.
Here are what man sed (the sed manual) says about the -E paremeter:
-E, -r, --regexp-extended
use extended regular expressions in the script (for portability use POSIX -E).
Next, we give sed a search pattern using the following format:
s/[search pattern]/[replace text]/g
If you are a Vim user, this will be very familiar as this is how you do find-and-replace in Vim.
Let’s take another look at the pattern:
"s/(^https?\:)?\/\//https\:\/\//g"
Search Pattern = (^https?\:)?\/\/
Replace Pattern = https\:\/\/
The search pattern is telling sed to look for lines that begin with //, https:// or http://. The carrot (^) is regex to indicate the start of a line.
The replace pattern is telling sed to replace with https://.
Hope that helps you better understand what is going on. Regex always looks scary but when broken down, it’s not that hard.
To conclude part one, let’s save the URLs to a text file called URLs.txt by adding the greater-than symbol to owner command. (> urlx.txt)
grep -E "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" page.html -o | sed "s/(^https?)?\/\//https\:\/\//g" -r > urls.txt
To make sure this worked perfectly, run the command cat urls.txt to see if all of the URLs print out.
Part Two: Downloading The Images
The hard part is behind us.
To download the images using wget, let’s use the following command:
wget -i urls.txt -P downloads/
If you run this command, all of the images from that Wikipedia page will download to a downloads/ folder in your current directory.
It’s important to mention what the -i and -P parameters do.
-i allows us to specify an input file. Without this paremeter, wget expects to download a single URL. For example wget dougie.io/s/ohmyzsh will download my ohmyzsh installation script. -i lets us specify a text file full of URLS.
Without the -P parameter, wget will download all images into our current directory. -P specifies the prefix of the output file - the folder where downloaded files will go.
To wrap up the very brief part 3, run ls downloads/ to see if the images do actually exist in that new downloads directory. Then open them with an image editor to make sure they are not somehow corrupted.
Part Three: Getting Full-Resolution Images From Wikipedia
We are so close! We have all of our images but they are at a super small thumbnail-size resolution. We are trying to get high-res wallpapers here so this is not acceptable.
First, let’s delete the images we just downloaded using rm -r downloads/*.
I <3 sed
Let’s compare the URLs of a Wikipedia thumbnail image to a full-res one. Look for patterns.
https://upload.wikimedia.org/wikipedia/commons/thumb/0/0d/Great_Wave_off_Kanagawa2.jpg/300px-Great_Wave_off_Kanagawa2.jpg
https://upload.wikimedia.org/wikipedia/commons/0/0d/Great_Wave_off_Kanagawa2.jpg
Oh my god…This is going to be so easy.
In order to transform a thumbnail URL into a full-res URL, we need to make the following changes to the URL:
- Remove
/thumb - Remove the last bit of the URL that follows the pattern
/[number]px-[filename].[file extension]
So, instead of modifying our command from part 1 and re-writing the urls.txt, let’s use urls.txt as a source and create a urls-new.txt.
We will be using sed to find-and-replace just like before.
It’s worth explaining that there are two ways to use sed on a file.
cat urls.txt | sed "s/search/replace/g"or…sed "s/search/replace/g" < urls.txt
The second way is the recommended way to do this as it removes the need to use a second program, cat.
Here’s the full command we will be using to modify the URLs and create urls-new.txt:
sed -E "s/\/thumb//g; s/\/[0-9]+px-.+\.(jpg|png)$//g" urls.txt > urls-new.txt
You will notice that we can actually use multiple find-and-replace patterns in sed as long as we separate them with semicolon.
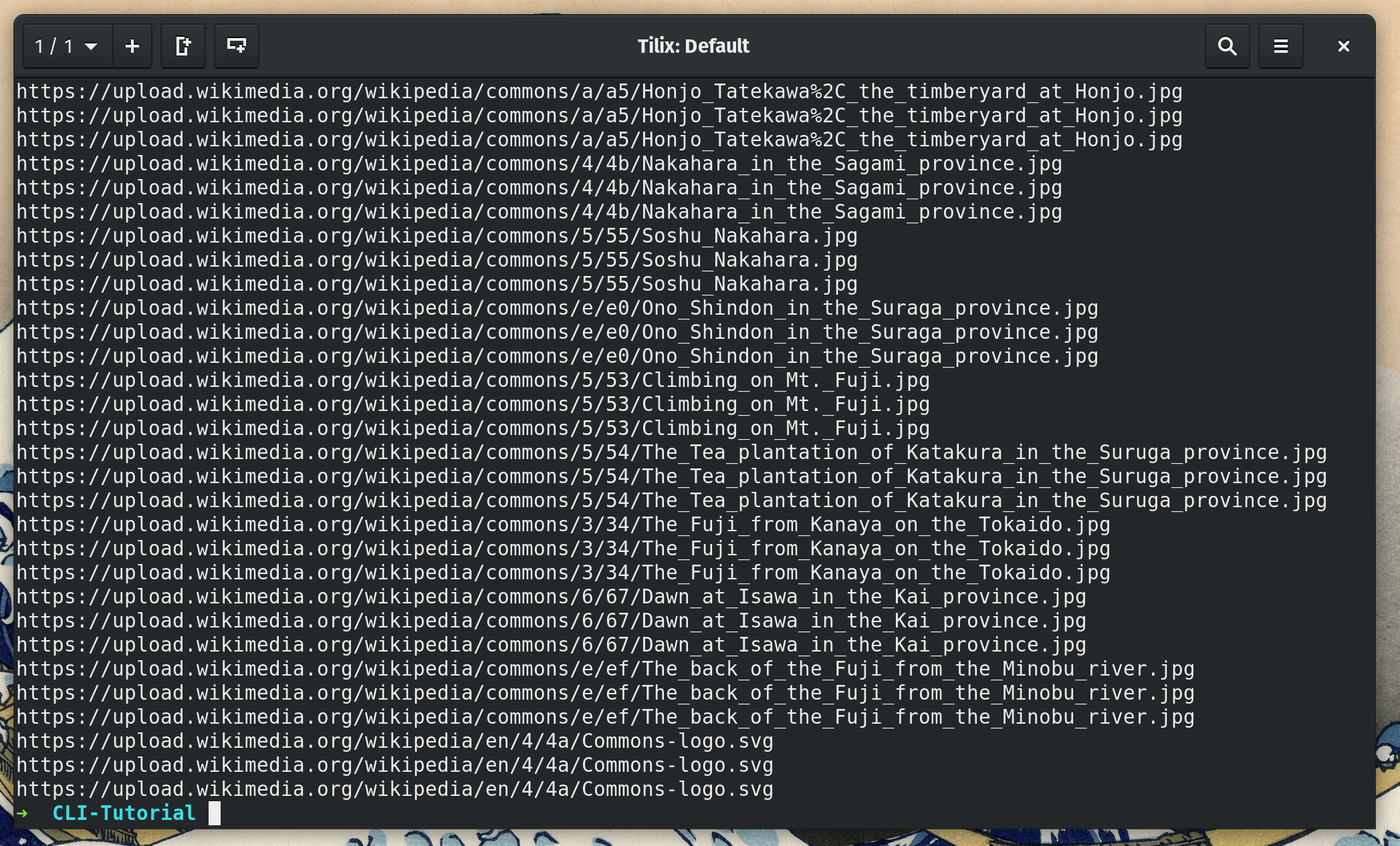
Only problem is that there are a lot of duplicate URLs. wget will overwrite files fine but having these duplicates will make for an inefficient program.
Luckily, this is an easy fix. Modify the command to pipe the URLs into the command uniq, which removes duplicates.
sed -E "s/\/thumb//g; s/\/[0-9]+px-.+\.(jpg|png)$//g" urls.txt | uniq > urls-new.txt
Run it again and you are all set.
Now for the moment of truth! Let’s run wget again.
wget -i urls-new.txt -P downloads/
Success!

Now, we have a bunch of great, full-resolution wallpapers. Thank you Wikipedia, Linux, and the public domain!
Part Four: Turning It Into a Script
No matter how much of a Linux guru you are, if every time you found a cool page with images you wanted to save, entering all of these commands would be a hassle. Let’s create a cool customizable script to automate all of the tedious bits.
The script will even allow you to input a URL to download images from.
I want you to first try this on your own and view my solution only if you need help. For a primer on shell scripts, check out CompCiv’s intro to creating shell scripts. Don’t be thrown off that he is using Mac OS X. It all works in Linux too.
A note about the scripts below: Instead of wget for getting HTML, I choose to use curl. Curl simply echos a website’s HTML to your terminal, instead of saving a file like wget.
Script for downloading images from a Wikipedia or Wikimedia.
You can alternatively download this script at dougie.io/s/imageGetterWikipedia.sh.
How to run:
sh imageGetterWikipedia.sh [url]
imageGetterWikipedia.sh
#!/bin/sh
# Get HTML of page from user's input, get all of the image links, and make sure URLs have HTTPs
curl $1 | grep -E "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" -o | sed "s/^(https?)?\/\//https\:\/\//g" -r > urls.txt
# Get full-res URLs instead of thumbnails and re-saving urls.txt
sed -Ei "s/\/thumb//g; s/\/[0-9]+px-.+\.(jpg|png)$//g" urls.txt
# Downloading Images
wget -i urls.txt -P downloads/Script for downloading images from other sites
You can alternatively download this script at dougie.io/s/imageGetter.sh.
imageGetter.sh
#!/bin/sh
# Get HTML of page from user's input, get all of the image links, and make sure URLs have HTTPs
curl $1 | grep -E "(https?:)?//[^/\s]+/\S+\.(jpg|png|gif)" -o | sed "s/^(https?)?\/\//https\:\/\//g" -r > urls.txt
# Downloading Images
wget -i urls.txt -P downloads/Further challenges
Here are some challenges if you are interested in taking this project further.
- Find a way to filter-out undesirable images (ex. Favicons, logos)
- Remove small images (Tiny images that would be no good for desktop wallpaper)
- Recreate this using the programming language of your choice
Final Notes
Of course, only use this script for legal purposes. If you somehow use this and get into copyright disputes for whatever reasons (Maybe you thought it’d be a good idea to start a free-wallpaper website with this script), I am not liable.
Btw, You can even browse Wikimedia to find pages full of cool photos. For example, this page of old-school stock exchanges works perfectly with our script.
Have fun!
Leave a comment